کارکردِ الگوی چامسکی در مطالعات قرآنی؛ یادداشتی از دکتر قاسم درزی

نگاه تک لایه ای و نگاه چندلایه ای. همچنین بیان کردیم که نگاه تک لایه ای با انقلاب معناشناختیِ چامسکی به شکل ویژه ای مطرح گردد. اما نگاه چندلایه ای پیش از این نیز کاملاً مسبوق به سابقه بوده است. تحقق نگاه چندلایه ای را مبتنی بر عبور از 5 لایه دانستیم: لایۀ تاریخی، لایۀ ساختاری(سوسور)، لایۀ قومی-فرهنگی، لایۀ شناختی، و لایۀ گفتمانی. به اعتقاد نویسندۀ این سطور عدم توجه به نگاه چندلایه ای، به تحویل و تقلیل[1] متن به هر یک از این لایه ها منجر خواهد شد. کاربرِ زبان برای اجتناب از چنین تحویل انگاری ای باید توجه ویژه ای به لایه های مختلف متن داشته باشد. همچنین باید قادر باشد به خوبی از علوم مرتبط با هر یک از این لایه ها استفاده نماید. در این جُستار تلاش خواهیم کرد به اختصار به برخی از کاربردهای این نگاه چندلایه ای در مطالعات قرآنی اشاره نماییم:
کاربردِ نگرشِ تک لایه ای در قرآن پژوهی: اگر زبان شناسیِ زایشی و دستور زبانی همگانی چامسکی را یکی از برجسته ترین نمونه های نگرشِ تک لایه ای به معناشناسی در نظر بگیریم، از سال 2000 به این طرف، کاربردِ آن در مطالعات دینی و به شکل خاصتر مطالعات قرآنی فزونی گرفته است. اعلی ترین نمونۀ این کاربردها را باید در درختواره های (Treebank) صرفی-نحوی جستجو کرد. چامسکی معتقد بود که از طریق یادگیری تعدا محدودی قاعده و واژه میتوان جملات نامحدودی را ساخت. او این قواعد را بر اساس نمودارهایی درختی تبیین کرد. از دیدگاه او هر جمله دارای دو عبارت اسمی (NP) و یک فعل (V) است. هر عبارت اسمی نیز از حرف اضافه (ART)، صفت (ADG) و اسم (N) ساخته شده است. او بر این اساس، و همچنین اضافه کردن چند فرمول دیگر، تمامی قواعد زبانی را در قالب نمودارهای درختی ترسیم کرد. او از این طریق توانست الگویی مشترک را برای تبیین تمامی زبانها ارائه نماید.
گسترده ترین و موثرترین استفاده از الگوی چامسکی در مطالعات قرآنی را باید در حوزه هوش مصنوعی و علوم کامپیوتر دانست. تاکنون چندین بانک درختی (Treebank) برای تجزیه و تحلیل زبان عربی و همچنین زبان قرآن تدوین شده است. بانک درختیِ دانشگاه کلمبیا برای زبان عربی (columbia arabic treebank)، بانک درختیِ دانشگاه پنسیلوانیا برای زبان عربی (The Penn Arabic Treebank)، و بانک درختیِ دانشگاه پراگ برای زبان عربی (Praugue Arabic Tree Bank) را باید اساسیترین نمونههای به کار بستن نمودارهای درختی چامسکی برای تحلیل و تجزیۀ زبان عربی دانست. نمودار درختی دانشگاه کلمبیا برای تجزیه و تحلیل صرفی و نحوی عبارات عربی یکی از سادهترین و کارآمدترینِ این سه منبع میباشد. برای آشنایی بیشتر مخاطبین با یان بحث، چند نمونه از نمودارهای دانشگاه کلمبیا را در زیر می آوریم:
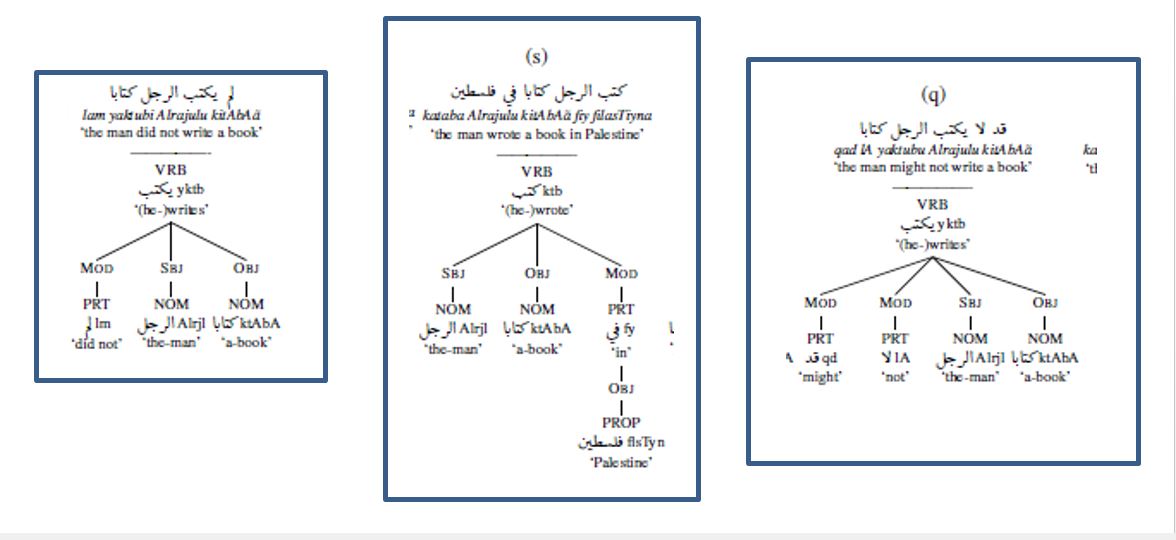
واضح است که در هر یک از این نمودارهای درختی، جملات بر اساسِ فعل ترسیم شده اند. به عنوان مثال در جملۀ “لم یکتب الرجل کتابا” در محله اول فعل “یکتب” قرار گرفته و در مرحله بعد نیز حرف اضافۀ “لم"، فاعل “الرجل” و مفعول “کتاب” قرار گرفته اند. اما جملۀ “کتب الرجل کتابا فی الفلسطین” به دلیل اینکه یک جار و مجرور اضافه تر به نسبت جملۀ پیشین دارد، فلسطین را به عنوان وابسته ای برای حرف اضافۀ “فی” در نظر میگیریم و از این جهت نمودار درختی ما گسترده تر خواهد شد. واضح است که در این نمودار درختی، اهمّ ویژگیهای صرفی و نحوی برای تحلیل جملات و تک گذاریِ آنها مورد نظر قرار میگیرند.
پس از این سه بانک درختی که برای زبان عربی ترسیم شده اند، شاهد بوده ایم که شخصی به نام کی آی دوکِز، در قالب رساله دکتریِ خود در دانشگاه ییل، به ترسیمِ بانک درختیِ زبان عربی بر اساس زبان قرآن مبادرت کرد. او توانست رساله دکتری خود را با نام “
Statistical Parsing by Machine Learning from a Classical Arabic Treebank” در سال 2013 دفاع کند. همانطور که از نام اثر او بر میآید، هدف اصلی او تجزیه و تحلیل آماریِ متن است که بوسیله یادگیریِ ماشین از بانک درختیِ کلاسیک عربی محقق میشود. منظور او از عربیِ کلاسیک، به شکل خاص عربیِ قرآنی است. او پس از ترسیمِ بانک درختیِ قرآنی، توانست محصولی کاربردی را ارائه نماید. سایت بسیار مهم http://corpus.quran.com، یکی از بهترین سایتهای هوشمندی است که میتواند به تجزیه و تحلیل هوشمند متن قرآن بپردازد. همچنین قادر است به کشف آیات و واژگان مشابه بپردازد. این سایت از معدود مراکزی است که تمام متن قرآنی را بر اساس الگوی چامسکی تک گذاری کرده است و از این طریق میتوان به سهولت به آنتولوژی و هستان شناسی قرآن دست یافت. در الگوهای هستان شناسانه، به دلیل اینکه تمام متن تک گذاری و علامت گذاری شده است، به خوبی میتوان ارتباطات صرفی، نحوی و معناییِ قسمتهای مختلف متن با یکدیگر را متوجه شد. سایت کورپوس یکی از معدود مراکزی است که قادر است ما را با چنین هستانشناسی ای مواجه کند.
بدون تردید، جدید بودنِ این بحث امکان آنرا برای ما به وجود نیاورد تا در این مختصر به تبیین بهتر و جامعتری از این بحث بپردازیم. اما نویسندۀ این سطور تلاش خواهد کرد تا در قالب مقالاتی جامعتر و مطول تر بیشتر به عوارض و جوانب و همچنین نواقص چنین کارهایی بپردازد. امید است که این مختصر توانسته باشد تا دریچه ای جدیدی از مطالعات قرآنی را به روی علاقه مندان به این بحث بازنماید.
برخی منابع:
Nizar Habash and Ryan Roth. 2009. CATiB: The Columbia Arabic Treebank. Technical Report CCLS- 09-01, Center for Computational Learning Systems, Columbia University;
Smrz, Otakar, Jan Šnaidauf, and Petr Zemánek. “Prague dependency treebank for Arabic: Multi-level annotation of Arabic corpus.” Proc. of the Intern. Symposium on Processing of Arabic. 2002;
Dukes, Kais. Statistical Parsing by Machine Learning from a Classical Arabic Treebank. Submitted in accordance with the requirements for the degree of Doctor of Philosophy, The University of Leeds School of Computing , September, 2013.
[1] - Reductionism.